








































Like every Big Tech company these days, Meta has its own flagship generative AI model, called Llama. Llama is somewhat unique among major models in that it’s “open,” meaning developers can download and use it however they please (with certain limitations). That’s in contrast to models like Anthropic’s Claude, Google’s Gemini, xAI’s Grok, and most of OpenAI’s ChatGPT models, which can only be accessed via APIs.
In the interest of giving developers choice, however, Meta has also partnered with vendors, including AWS, Google Cloud, and Microsoft Azure, to make cloud-hosted versions of Llama available. In addition, the company publishes tools, libraries, and recipes in its Llama cookbook to help developers fine-tune, evaluate, and adapt the models to their domain. With newer generations like Llama 3 and Llama 4, these capabilities have expanded to include native multimodal support and broader cloud rollouts.
Here’s everything you need to know about Meta’s Llama, from its capabilities and editions to where you can use it. We’ll keep this post updated as Meta releases upgrades and introduces new dev tools to support the model’s use.
What is Llama?
Llama is a family of models — not just one. The latest version is Llama 4; it was released in April 2025 and includes three models:
- Scout: 17 billion active parameters, 109 billion total parameters, and a context window of 10 million tokens.
- Maverick: 17 billion active parameters, 400 billion total parameters, and a context window of 1 million tokens.
- Behemoth: Not yet released but will have 288 billion active parameters and 2 trillion total parameters.
(In data science, tokens are subdivided bits of raw data, like the syllables “fan,” “tas,” and “tic” in the word “fantastic.”)
A model’s context, or context window, refers to input data (e.g., text) that the model considers before generating output (e.g., additional text). Long context can prevent models from “forgetting” the content of recent docs and data, and from veering off topic and extrapolating wrongly. However, longer context windows can also result in the model “forgetting” certain safety guardrails and being more prone to produce content that is in line with the conversation, which has led some users toward delusional thinking.
For reference, the 10 million context window that Llama 4 Scout promises roughly equals the text of about 80 average novels. Llama 4 Maverick’s 1 million context window equals about eight novels.
Techcrunch event
San Francisco
|
October 27-29, 2025
All of the Llama 4 models were trained on “large amounts of unlabeled text, image, and video data” to give them “broad visual understanding,” as well as on 200 languages, according to Meta.
Llama 4 Scout and Maverick are Meta’s first open-weight natively multimodal models. They’re built using a “mixture-of-experts” (MoE) architecture, which reduces computational load and improves efficiency in training and inference. Scout, for example, has 16 experts, and Maverick has 128 experts.
Llama 4 Behemoth includes 16 experts, and Meta is referring to it as a teacher for the smaller models.
Llama 4 builds on the Llama 3 series, which included 3.1 and 3.2 models widely used for instruction-tuned applications and cloud deployment.
What can Llama do?
Like other generative AI models, Llama can perform a range of different assistive tasks, like coding and answering basic math questions, as well as summarizing documents in at least 12 languages (Arabic, English, German, French, Hindi, Indonesian, Italian, Portuguese, Hindi, Spanish, Tagalog, Thai, and Vietnamese). Most text-based workloads — think analyzing large files like PDFs and spreadsheets — are within its purview, and all Llama 4 models support text, image, and video input.
Llama 4 Scout is designed for longer workflows and massive data analysis. Maverick is a generalist model that is better at balancing reasoning power and response speed and is suitable for coding, chatbots, and technical assistants. And Behemoth is designed for advanced research, model distillation, and STEM tasks.
Llama models, including Llama 3.1, can be configured to leverage third-party applications, tools, and APIs to perform tasks. They are trained to use Brave Search for answering questions about recent events; the Wolfram Alpha API for math- and science-related queries; and a Python interpreter for validating code. However, these tools require proper configuration and are not automatically enabled out of the box.

Where can I use Llama?
If you’re looking to simply chat with Llama, it’s powering the Meta AI chatbot experience on Facebook Messenger, WhatsApp, Instagram, Oculus, and Meta.ai in 40 countries. Fine-tuned versions of Llama are used in Meta AI experiences in over 200 countries and territories.
Llama 4 models Scout and Maverick are available on Llama.com and Meta’s partners, including the AI developer platform Hugging Face. Behemoth is still in training. Developers building with Llama can download, use, or fine-tune the model across most of the popular cloud platforms. Meta claims it has more than 25 partners hosting Llama, including Nvidia, Databricks, Groq, Dell, and Snowflake. And while “selling access” to Meta’s openly available models isn’t Meta’s business model, the company makes some money through revenue-sharing agreements with model hosts.
Some of these partners have built additional tools and services on top of Llama, including tools that let the models reference proprietary data and enable them to run at lower latencies.
Importantly, the Llama license constrains how developers can deploy the model: App developers with more than 700 million monthly users must request a special license from Meta that the company will grant on its discretion.
In May 2025, Meta launched a new program to incentivize startups to adopt its Llama models. Llama for Startups gives companies support from Meta’s Llama team and access to potential funding.
Alongside Llama, Meta provides tools intended to make the model “safer” to use:
- Llama Guard, a moderation framework.
- CyberSecEval, a cybersecurity risk-assessment suite.
- Llama Firewall, a security guardrail designed to enable building secure AI systems.
- Code Shield, which provides support for inference-time filtering of insecure code produced by LLMs.
Llama Guard tries to detect potentially problematic content either fed into — or generated — by a Llama model, including content relating to criminal activity, child exploitation, copyright violations, hate, self-harm, and sexual abuse.
That said, it’s clearly not a silver bullet since Meta’s own previous guidelines allowed the chatbot to engage in sensual and romantic chats with minors, and some reports show those turned into sexual conversations. Developers can customize the categories of blocked content and apply the blocks to all the languages Llama supports.
Like Llama Guard, Prompt Guard can block text intended for Llama, but only text meant to “attack” the model and get it to behave in undesirable ways. Meta claims that Llama Guard can defend against explicitly malicious prompts (i.e., jailbreaks that attempt to get around Llama’s built-in safety filters) in addition to prompts that contain “injected inputs.” The Llama Firewall works to detect and prevent risks like prompt injection, insecure code, and risky tool interactions. And Code Shield helps mitigate insecure code suggestions and offers secure command execution for seven programming languages.
As for CyberSecEval, it’s less a tool than a collection of benchmarks to measure model security. CyberSecEval can assess the risk a Llama model poses (at least according to Meta’s criteria) to app developers and end users in areas like “automated social engineering” and “scaling offensive cyber operations.”
Llama’s limitations
Llama comes with certain risks and limitations, like all generative AI models. For example, while its most recent model has multimodal features, those are mainly limited to the English language for now.
Zooming out, Meta used a dataset of pirated e-books and articles to train its Llama models. A federal judge recently sided with Meta in a copyright lawsuit brought against the company by 13 book authors, ruling that the use of copyrighted works for training fell under “fair use.” However, if Llama regurgitates a copyrighted snippet and someone uses it in a product, they could potentially be infringing on copyright and be liable.
Meta also controversially trains its AI on Instagram and Facebook posts, photos, and captions, and makes it difficult for users to opt out.
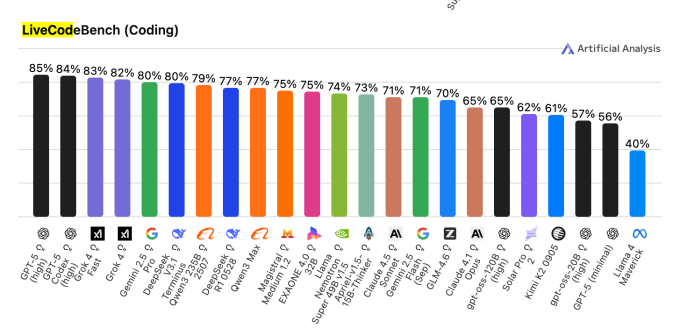
Programming is another area where it’s wise to tread lightly when using Llama. That’s because Llama might — perhaps more so than its generative AI counterparts — produce buggy or insecure code. On LiveCodeBench, a benchmark that tests AI models on competitive coding problems, Meta’s Llama 4 Maverick model achieved a score of 40%. That’s compared to 85% for OpenAI’s GPT-5 high and 83% for xAI’s Grok 4 Fast.
As always, it’s best to have a human expert review any AI-generated code before incorporating it into a service or software.
Finally, as with other AI models, Llama models are still guilty of generating plausible-sounding but false or misleading information, whether that’s in coding, legal guidance, or emotional conversations with AI personas.
This was originally published on September 8, 2024, and is updated regularly with new information.









